by Dom Bowker
I have been fascinated by some of the new features in the latest tools releases but, if you are like me and struggle to keep up to date with the latest developments, you may see the learning curve as too steep, or too time-consuming, to begin the journey. However, I’ve recently discovered how easy Oracle has made it to add simple automation to your system admin and improve system availability by using the health-check feature within JD Edwards Server Manager and combining this with Orchestrator, to automate and schedule health-checks.
Server Manager Health Check
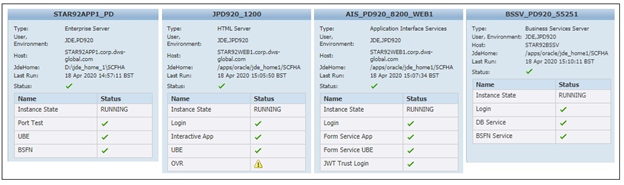
The health-check functionality has been available in Server Manager since Tools Release 9.2.2.0. This allows tests to be run against your different JDE server types, Enterprise, BSSV, HTML, AIS etc… to ensure they are online and available for processing. Details of the configuration and the tests can be found here:
These features are exposed using REST APIs and are accessible by any REST client such as Postman, Ruby, etc… And since tools 9.2.3.4 it has been possible to access these by creating Service Requests in the JD Edwards Orchestrator. A complete list of the available REST APIs can be found here.
Automating with Orchestrator
This simple tutorial from Oracle, which takes about 30 minutes to complete, walks through the process of creating an Orchestration that will use the REST APIs to run an automated server manager health check and provide an email notification if the test fails. Click here for the tutorial.
Please note that at the time of print the tutorial contains a typo in the Groovy script and an extra single quote is required at the end of line 21 i.e. ‘ + ‘Instance Status : ‘ + instance.instanceStatus + ‘‘
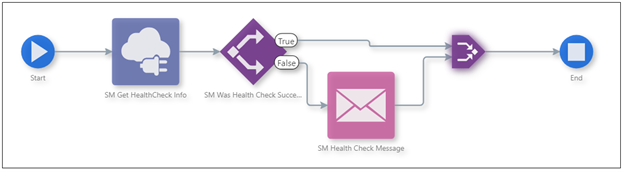
Using the scheduler functionality built into Orchestrator we can now schedule regular automated health-checks to monitor the JD Edwards infrastructure and receive alerts when servers are not running correctly.
If you are still running manual proactive system checks on your JD Edwards system and have several of each server type you could easily be spending 15-20 mins for a complete system check. This can quickly add up even if only one test per day is performed, so the benefit of automated testing can mean big savings in time.
Scheduler resilience
Now that we are relying on automated health checks to replace our manual proactive checks, we want to make sure the process running the checks does not fail! To help with this we can take advantage of Scheduler Resilience.
With an additional installation of Orchestrator (or AIS since 9.2.4) and the use of its Scheduler Resilience function we can build in a backup system to keep the checks running even if an AIS server should fail. The setup document for Scheduler Resilience is here.
DWS thoroughly recommends upgrading to Tools Release 9.2.4.X which bundles Orchestrator in with the AIS server, a huge simplification, and provides a more user-friendly interface for managing the scheduler.
Putting it all together
This fits nicely into Oracles concept architecture for a high availability JD Edwards solution that allows servers to be taken offline for package deploys, windows updates, or other maintenance without interrupting 24*7 operations.
Documented in Oracle Doc ID 1325593.1, this remarkably simple but effective ACTIVE-ACTIVE solution for providing 24*7 operations combines enterprise and web servers in groups that can be withdrawn from service for maintenance when combined with a load balancer.
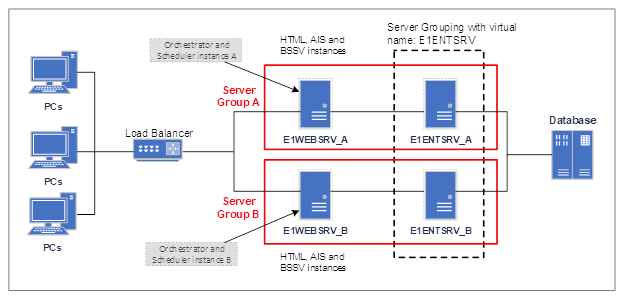
Configuring the servers in this way provides the ideal platform for the resilient scheduled health check, or any other scheduled orchestration for that matter.
This is a great solution for any customers that have difficulty scheduling maintenance windows and can be expanded with additional server groups without any complicated clustering software.
Extending this idea further with additional service requests our health-check orchestration can:
- Instruct the load balancer, possibly by uploading a new config file using FTP, to stop directing traffic to a failed server group.
- Email users on the failed server group to re-log and get directed to the working server group.
- Automatically restart the failed instance and test that it is now running correctly.
- Use a successful test to instruct the load balancer to restore traffic to the server group.
DWS has been working with customers to help them simplify and automate their system administration and if you would like to know more about achieving rapid results with EnterpriseOne Orchestrator then please get in touch. You can read more about this theme in Oracles latest Statement of Direction.
If you would like to automate your server manager health-checks but don’t have 30 minutes to create your own Orchestration then give me a shout and I will send you a copy of mine that can be imported into your own system in seconds!



